The error that you encountered in HDFView 3.0 Beta (“type is not variable length string”) is a known bug (HDFVIEW-41).
We will be fixing it for the released version of HDFView 3.0, due out later this year.
I’m not sure about the performance issue. Have you tried looking at the slow files with the h5dump utility that comes with
the binary distribution of HDF5? Is h5dump slow, as well? We are aware of performance issues with variable length types in Java,
but if h5dump is slow as well, then it would be good to understand the issue further.
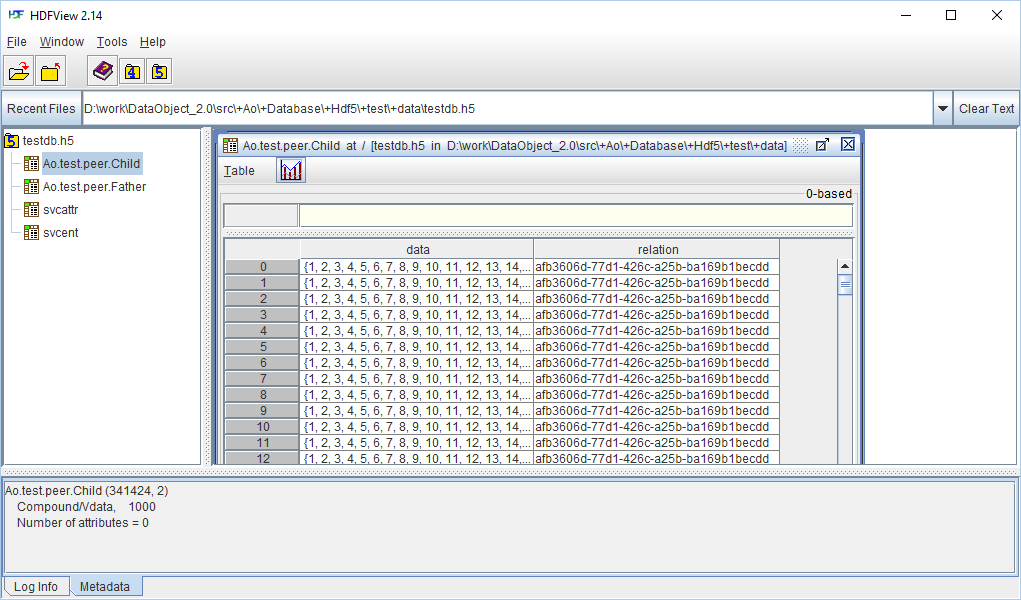
I looked at the testdb.h5 file that you sent with both HDFView 2.14 and h5dump and did not notice a performance issue. Can you send
us a file that you are having a problem with? Please send it to the HDF Helpdesk: help@hdfgroup.org
···
From: Hdf-forum [mailto:hdf-forum-bounces@lists.hdfgroup.org] On Behalf Of Daniel Rimmelspacher
Sent: Tuesday, January 30, 2018 2:48 PM
To: hdf-forum@lists.hdfgroup.org
Subject: [Hdf-forum] Fwd: Re: Hdf Viewer Slow on opening Compound dataset
Thanks!
-------- Weitergeleitete Nachricht --------
Betreff:
Re: [Hdf-forum] Hdf Viewer Slow on opening Compound dataset
Datum:
Tue, 30 Jan 2018 20:10:14 +0000
Von:
Ted Habermann <thabermann@hdfgroup.org><mailto:thabermann@hdfgroup.org>
An:
Daniel Rimmelspacher <danervt@hotmail.com><mailto:danervt@hotmail.com>
Daniel,
Looks like this email went just to me… better to get it on the forum because we are now past my experience... I will ping our help desk to try to focus some attention…
Ted
==== Ted Habermann ========================
Director of Earth Science, The HDF Group
Voice: (217) 531-4202
Email: thabermann@hdfgroup.org<mailto:thabermann@hdfgroup.org>
==== HDF: Software That Powers Science ====
From: Daniel Rimmelspacher <danervt@hotmail.com><mailto:danervt@hotmail.com>
Date: Tuesday, January 30, 2018 at 12:36 PM
To: "thabermann@hdfgroup.org"<mailto:thabermann@hdfgroup.org> <thabermann@hdfgroup.org><mailto:thabermann@hdfgroup.org>
Subject: Re: [Hdf-forum] Hdf Viewer Slow on opening Compound dataset
Ted,
thanks for the hint!
I've tried Version3 but encounter new problems on opening the data set (please see figures below). I've attached a sample file.
Is this a known issue?
Thanks,
Daniel
[cid:part1.866BE529.097BDFA3@hotmail.com]
[cid:part2.2A7784B9.4F507708@hotmail.com]
Am 30.01.2018 um 17:17 schrieb Ted Habermann:
Daniel,
Sorry to hear you are having problems with HDFView. I am not an expert on this application, but I think that Version 3 which is available at https://www.hdfgroup.org/downloads/hdfview/#features has some significant improvements with regard to compound types and large files. Is it possible to try out the most current version?
Ted Habermann
==== Ted Habermann ========================
Director of Earth Science, The HDF Group
Voice: (217) 531-4202
Email: thabermann@hdfgroup.org<mailto:thabermann@hdfgroup.org>
==== HDF: Software That Powers Science ====
From: Hdf-forum <hdf-forum-bounces@lists.hdfgroup.org><mailto:hdf-forum-bounces@lists.hdfgroup.org> on behalf of SIVA M <sivasivajimay14@gmail.com><mailto:sivasivajimay14@gmail.com>
Reply-To: HDF Users Discussion List <hdf-forum@lists.hdfgroup.org><mailto:hdf-forum@lists.hdfgroup.org>
Date: Tuesday, January 30, 2018 at 6:46 AM
To: HDF Users Discussion List <hdf-forum@lists.hdfgroup.org><mailto:hdf-forum@lists.hdfgroup.org>
Subject: Re: [Hdf-forum] Hdf Viewer Slow on opening Compound dataset
HDF Format to ascii format how to convert please explane anybody
On Tue, Jan 30, 2018 at 2:36 AM, Daniel Rimmelspacher <danervt@hotmail.com<mailto:danervt@hotmail.com>> wrote:
Dear Forum Members,
please let me enhance the provided information:
1. I am using HdfView-2.14.0.
2. This is the questionable data set.
[cid:part1.DF129088.3B54D0CE@hotmail.com]
3. These are the data set properties.
[cid:part2.DE26C0F3.C4C05130@hotmail.com]
Can someone provide information about possible steps in order to track the problem further down?
Thanks and kind regards,
Daniel
Am 29.01.2018 um 00:06 schrieb Daniel Rimmelspacher:
Dear Forum Members,
I am trying to store application data in a compound dataset (via Matlab
low-level API). The dataset looks like this:
Column1:
type1 = H5T.vlen_create('H5T_NATIVE_DOUBLE')
Column2:
type2= H5T.copy('H5T_C_S1')
H5T.set_size(type2, 'H5T_VARIABLE')
In order to try out the performance, I varied the length of type 1, i.e.
storing 10/100/1000/10000 doubles in 10000 rows. Storing though seems
pretty fast, but when I try to open the data set with the HDF Viewer I
encounter significant performance issues for 10000 values. I already
tried to vary the chunking parameter (1/10/100/1000) but without success.
Is this an issue with the HDF viewer or rather a problem with my data
model? Is there a trick in order to enhance dataset loading performance
inside the viewer?
Any hint is appreciated!
Thanks,
Daniel
_______________________________________________
Hdf-forum is for HDF software users discussion.
Hdf-forum@lists.hdfgroup.org<mailto:Hdf-forum@lists.hdfgroup.org>
http://lists.hdfgroup.org/mailman/listinfo/hdf-forum_lists.hdfgroup.org
Twitter: https://twitter.com/hdf5
_______________________________________________
Hdf-forum is for HDF software users discussion.
Hdf-forum@lists.hdfgroup.org<mailto:Hdf-forum@lists.hdfgroup.org>
http://lists.hdfgroup.org/mailman/listinfo/hdf-forum_lists.hdfgroup.org
Twitter: https://twitter.com/hdf5
_______________________________________________
Hdf-forum is for HDF software users discussion.
Hdf-forum@lists.hdfgroup.org<mailto:Hdf-forum@lists.hdfgroup.org>
http://lists.hdfgroup.org/mailman/listinfo/hdf-forum_lists.hdfgroup.org
Twitter: https://twitter.com/hdf5