I wish to transform a data set of size (512, 513, 513) into a data set containing the 2 first axis at a specific location of the 3rd axis. Suppose I want to select the 100th point of the 3rd axis.
I use h5copy -i continua_vz_0010 -o temp.h5 -s “Vz[:,:,100]” -d “sliced_data” . Provided below is the data structure of “continua_vz_0100”. The temp file is created but nothing is copied inside. The error provided says “Error in copying… exiting”. The file is simply created at the end of a simulation. Are there other alternatives to splice the data because reading lots 512^3 files with python is not efficient
h5copy only allows you to copy the whole object instead of the subset of the object.
So the syntax -s “Vz[:,:,100]” is not right. After -s only the object name needs to be provided.
You may write a simple python program by using h5py to do what you like to accomplish.
Thank you for the quick response! Is there a way to slice up arrays without first opening them in python? I tried using h5dump but I get an error stating that the file I wish to copy in cannot be opened.
I am currently opening it using h5py in a python script but this takes too much time. I have 50 of these 512^3 arrays and it takes roughly 40 minutes to make a (50, 512, 512) array. I this just the time it is supposed to take? I am not very familiar with h5 files so I apologize for any “stupid questions”.
In your original program, do not read each 512^3 file completely. Just use slicing syntax to read only the desired Vz[:,:,100] slice from each of 50 input files. H5py supports slicing on input, and the contiguous storage file layout will support efficient input slicing. This way, you also avoid the need for an intermediate file.
for t in range(len(N)):
hfz = h5py.File(‘256/continuation/continua_vz_{}’.format(N[t]), ‘r’)
vz[t] = hfz[‘Vz’][:, : ,126]
if count % 10 == 0:
print(count)
count += 1
print(“%s seconds” % (time.time() - start_time))
This is my current code and I think this is how to slice it on input but when comparing the execution time between this and the version without the slicing (Simply vz[t] = hfz[‘Vz’], while adapting the size of the original array, vz), they are pratically the same. The execution takes roughly 1 second per slice for the smaller grid size but maybe this is already as fast as it gets?
Thank you for taking the time to read and reply to my questions.
Regards,
Theo
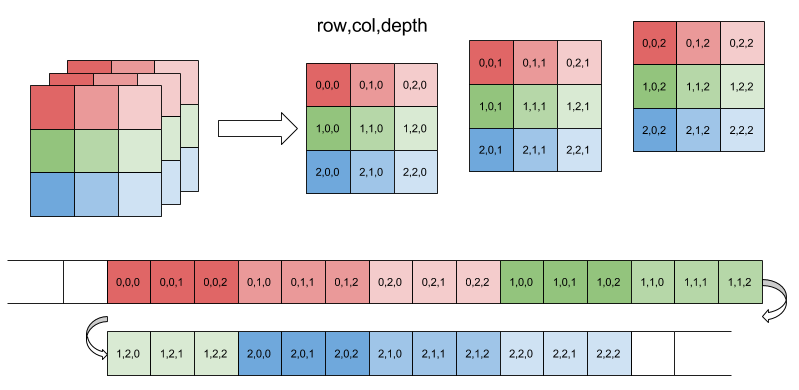
The type of read operation you are doing generally yields poor performance due to selection of specific elements in the array outermost dimension. Below is a diagram I borrowed from this blog that applies to a 3d array, not-chunked, stored in the row-major (C-style) order. I made these assumptions because you did not report the actual storage settings of your input datasets.
What you are trying to read is something like one of the rectangles in upper half of the diagram, for example, [:,:,2] with elements [(0,0,2), (0,1,2), (0,2,2), (1,0,2), … (1,2,2), (2,0,2, … (2,2,2)]. Look how these elements are arranged in the file. There is no simple way to read a lot of the selected array elements efficiently and that is the reason for poor performance.
Is what you want to do a one-time job? If not, is it possible to rearrange the array dimensions differently? Is there any physical meaning to each dimension of your input arrays?
I think this is exactly the problem! I ran the code with [0, :, :] as slice and it goes 100x faster.
This is not really a one-time job unfortunately. The 3D array represents a flowfield with x, y, z axis as height, width and depth.
I do think rearranging the array would solve the issue as I can just swap the order again in the output but I really am not familiar with manipulating h5 files.
Aleksandar, thank you for the detailed explanation. “Contiguous” is actually reported in the original message above.
In my previous reply, I failed to notice that [:,:,n] (Python ordering) is a worst case scenario for reading a contiguous-stored array. There are no contiguous elements in that slicing, so every element has to be fetched individually. In contrast, the slice [n,:,:] is fully contiguous in the file, so the entire slice can be fetched in a single block transfer.
Theo, I see several options to fix your issue. These assume that the data from your original slice [:,:,n] is required.
Write a brief repacking program to extract the slice [:,:,n] from each of 50 input arrays, and combine the 50 slices into a single new file. Then the new file can be read repeatedly and efficiently by your application.
Write a brief repacking program to change the dimension order from [x,y,z] to [z,x,y] in a new file. Run this separately for each of 50 input files to create 50 new, 512^3 files. This new file set can now be read efficiently by your application.
Write a brief repacking program to keep the SAME dimension order [x,y,z], but change the storage layout from contiguous to chunked (512, 513, 1). Run this separately for each of 50 input files to create 50 new, 512^3 files. This new layout will also be read efficiently by your application.
Modify the original generating program to write original files using one of the storage strategies (2) or (3) above.
Now that you understand the performance problem, don’t change anything and accept the slow performance.
(4) would be best if you have the flexibility to change the generating program, because this will avoid large intermediate files and an extra processing step.
Aleksandar’s questions are relevant to choosing your best option.