Hello Folks,
I have a MPI cluster workflow that generate millions of small datasets in parallel. So far I have it programed where all the worker ranks, send these small datasets to rank-0, where it is written to an HDF5 file serially. The bottleneck is storing the data. I have read the HDF5 documentation extensively and see many possible solutions. So, I just wanted to get some advice on the best approach and avoid wasting time on a bad solution.
There is the MPI file driver, however, the only examples I have seen on that is when you have many ranks writing to the same dataset. So it seems that driver is meant for large distributed datasets. Does that work for writing many small datasets from multiple processes? One concern I have is the fact that file system IO becomes very slow on our cluster when the you have access on different nodes. If you can keep all the IO on a single node it’s better (not great, but better).
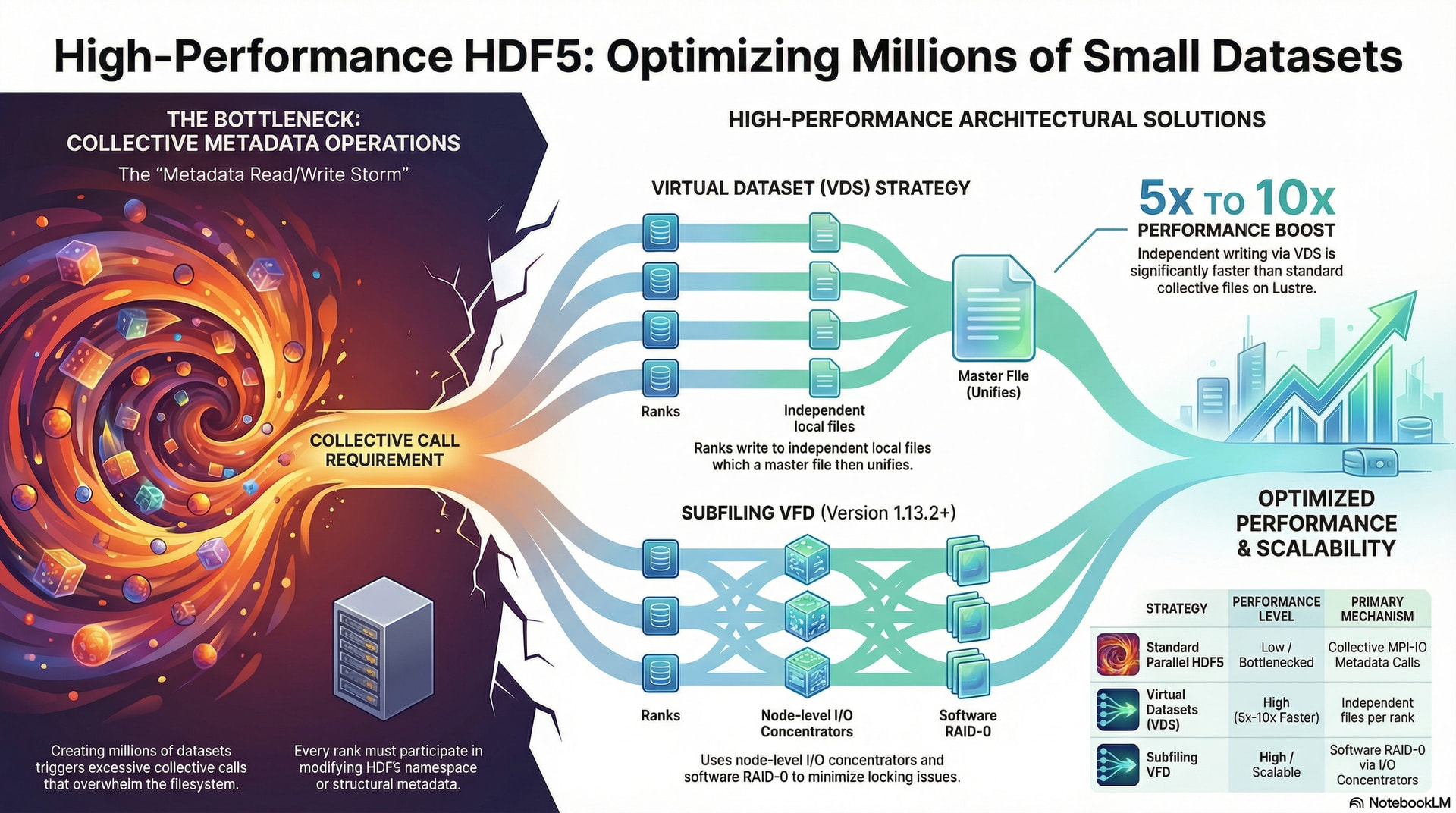
Given the IO limitations of our cluster … I was also looking for solutions where each rank/node could have their own local hdf5 file. I see that there is a multi-file driver for example. However, I guess that you would still have to open the root file. Then internally the library opens all the other multi-file parts as needed. So, it wasn’t clear how I could control multi-file so ranks could control a file exclusively. Maybe there is something I am missing?
The solution that seems most suitable, maybe not as elegant … is the mount option. I can create hdf5 files separately by each rank. Then use the mount functionality to read the data later in a transparent way. It’s not as elegant … but it’s at least a solution that I know for certain that I can have parallel writes. I can see that you can define linkages built into a file, so these other files can be mounted automatically. So, subsequent data processing doesn’t need to have detailed information on the multi-file structure.
My final option is similar to above, separate files per rank. But then use h5copy after to combine later into 1 file. Is h5copy extra efficient? does it just append data to the file efficiently? Or does it still get stuck having to unpack and decompress, just to rebuild it all over again.
Thank-you all for you helpful advice!
Mike